|
I am a Software Engineer at Meta's MRS (Meta Recommendation System) org, specifically working on Search and Recommendation for Facebook. I focus on building large-scale machine learning and LLM-based systems for search query retrieval and ranking, powering key entry points of Facebook Search such as Typeahead, Recent Search, and the Suggested Module. I completed my M.S.E. in Computer and Information Science from University of Pennsylvania, School of Engineering and Applied Science in 2025, where I also served as the Head Teaching Assistant for the graduate-level Machine Learning course. I graduated from Wake Forest University with a B.S. in Computer Science (with Honors) and a B.S. in Mathematical Business in 2023. My academic and professional work spans LLMs, Generative Modeling, Reinforcement Learning (robustness, safety, and explainability), and machine learning systems. I previously conducted research under Dr. Sarra Alqahtani at Wake Forest University and interned at IBM Research , where I worked on Mixture-of-Experts NLP systems and co-authored a U.S. patent. My current interests focus on building reliable, efficient, and trustworthy AI systems at scale. Email / LinkedIn / GitHub / Google Scholar |

|
|
|

|
M.S.E in Computer and Information Science 2023.08 - 2025.05 |

|
B.S in Computer Science (with honors) [Honor Thesis] B.S. in Mathematical Business 2019.08 - 2023.05 |
|
|

|
Menlo Park, CA 2025.06 - Present Software Engineer - MRS Search - Facebook |

|
San Jose, CA 2024.05 - 2024.08 Software Engineer Intern - Seed (Doubao) - Machine Learning System |

|
San Jose, CA 2022.05 - 2022.08 Research Intern - Almaden Research Lab @ San Jose |
|
|
My general research interests lie in different topics of Machine Learning, including data mining, foundation model based chatbot system in NLP, and security, safety, and robustness of Reinforcement Learning.
|
|
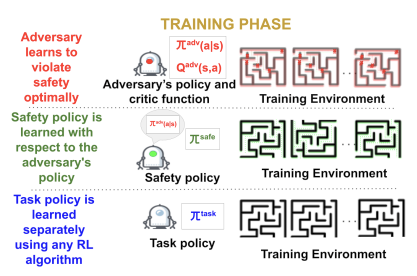
Md Asifur Rahman, Tongtong Liu , Sarra Alqahtani IJCAI, 2023 [paper] Adversarial Behavior Exclusion for Safe RL (AdvEx-RL) learns a behavioral representation of the agent’s safety violations by approximating an optimal adversary utilizing exploration and later uses this representation to learn a separate safety policy that excludes those unsafe behaviors. |
|
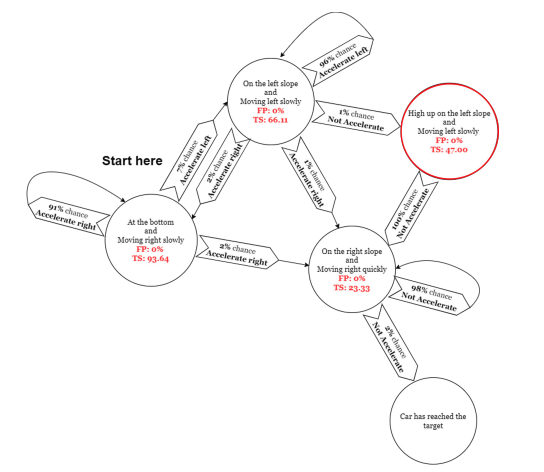
Tongtong Liu , Joe McCalmon, Thai Le, Dongwon Lee, Sarra Alqahtani AAMAS Journal, 2023 [paper]
In this work, we proposea novel approach that summarizes an agent’s policy in the form of a directed graph with natural language descriptions that help end user to understand the logic behind agent's decision.
|
|
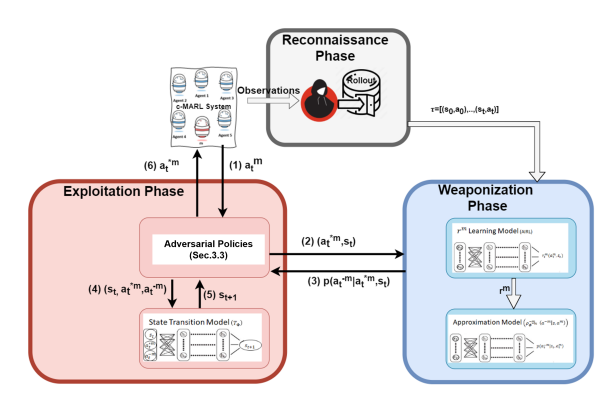
Tongtong Liu, Joe McCalmon, Md Asifur Rahman, Cameron Lischke, Talal Halabi, Sarra Alqahtani PRIMA, 2022 [paper] [code]
This paper investigates the robustness of c-MARL to a novel adversarial threat, where we target and weaponize one agent, termed the compromised agent, to create natural observations that are adversarial for its team. This paper shows mathematically the exploitation steps of such an adversarial policy in the centralized-learning and decentralized-execution paradigm of c-MARL.
|
|
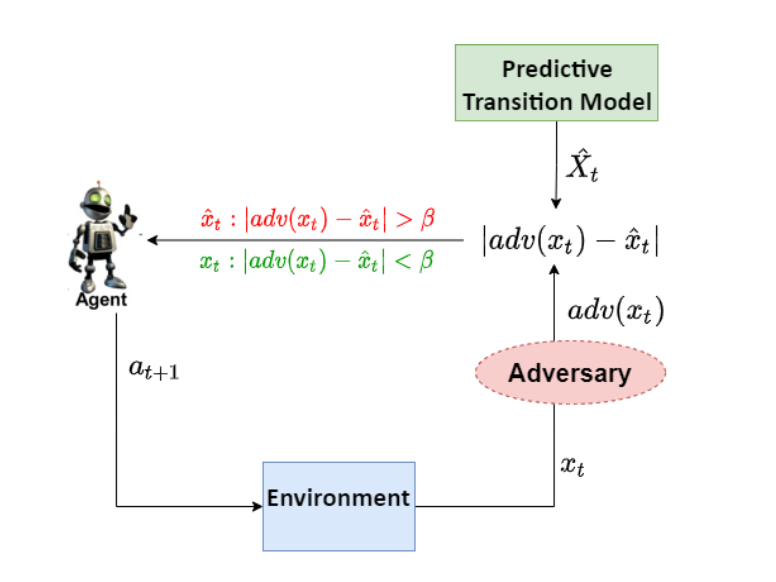
Joe McCalmon, Tongtong Liu , Reid Goldsmith, Andrew Cyhaniuk, Talal Halabi, Sarra Alqahtani HICSS, 2023 [paper] [code] We proposed a method called observation-shielding RL (OSRL) to increase the robustness of RL against large perturbations using predictive models and threat detection. OSRL builds on the idea of model predictive shielding, where an observation predictive model is used to override the perturbed observations as needed to ensure safety. |
|
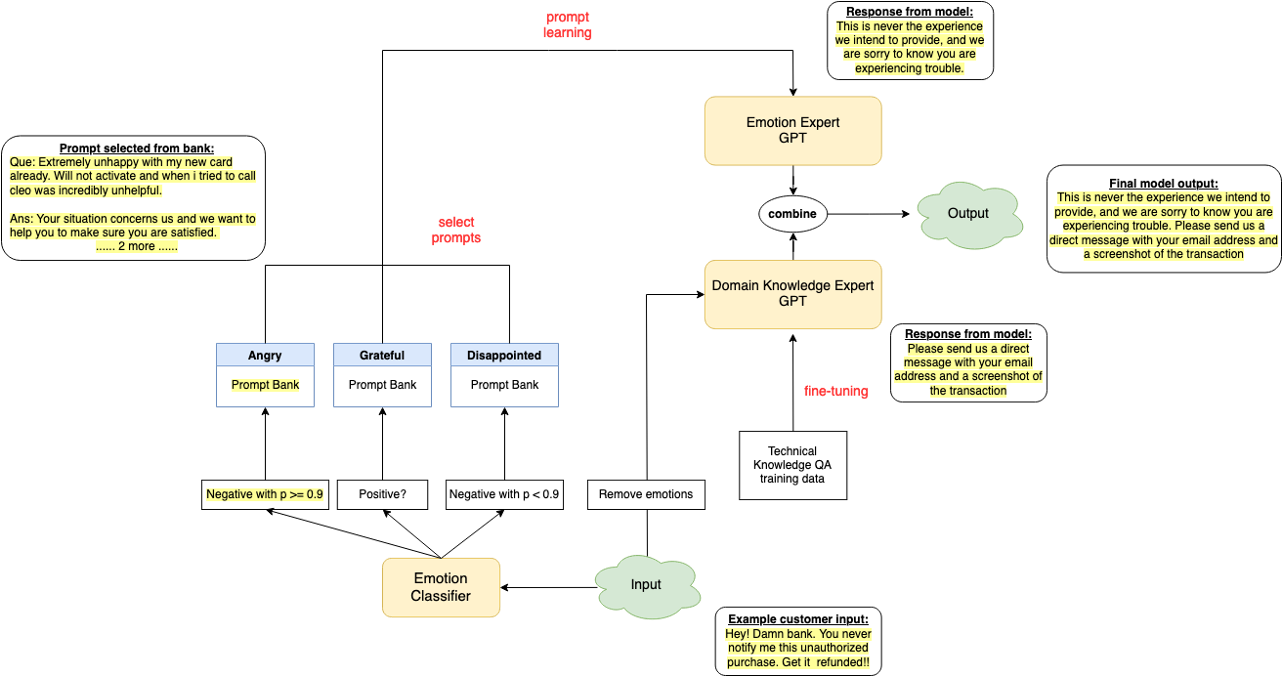
Tongtong Liu , Mu Qiao, Divyesh Jadav IBM Research Internship, 2022 [patent] We proposed a novel mixture of expert method that combines few-shot learning and model fine-tuning on the SOTA foundation model decoder -- GPT -- to build a customer service chatbot that can respond to offensive customer complaints in a professional and empathetic way.
|
|
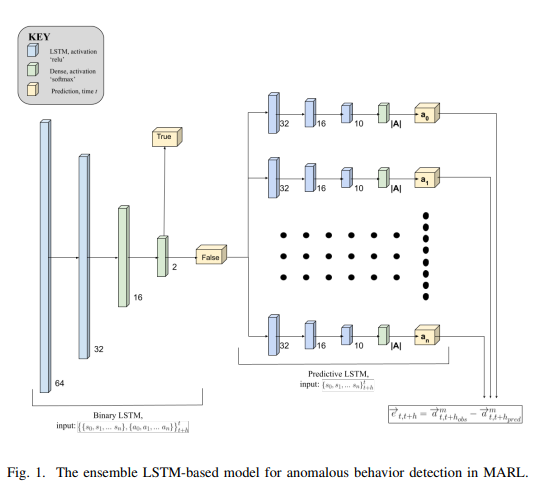
Cameron Lischke, Tongtong Liu , Joe McCalmon, Md Asifur Rahman, Talal Halabi, Sarra Alqahtani IEEE CSR, 2022 [paper] [code] We present a novel stacked-LSTM ensemble approach to detect a serious vulnerability in Multi-agent Reinforcement Learning system, compromised agent attack, which one of the agent in the team is controlled by an attacker to subsequently pushes its cooperative agents to act off-policy. |
|
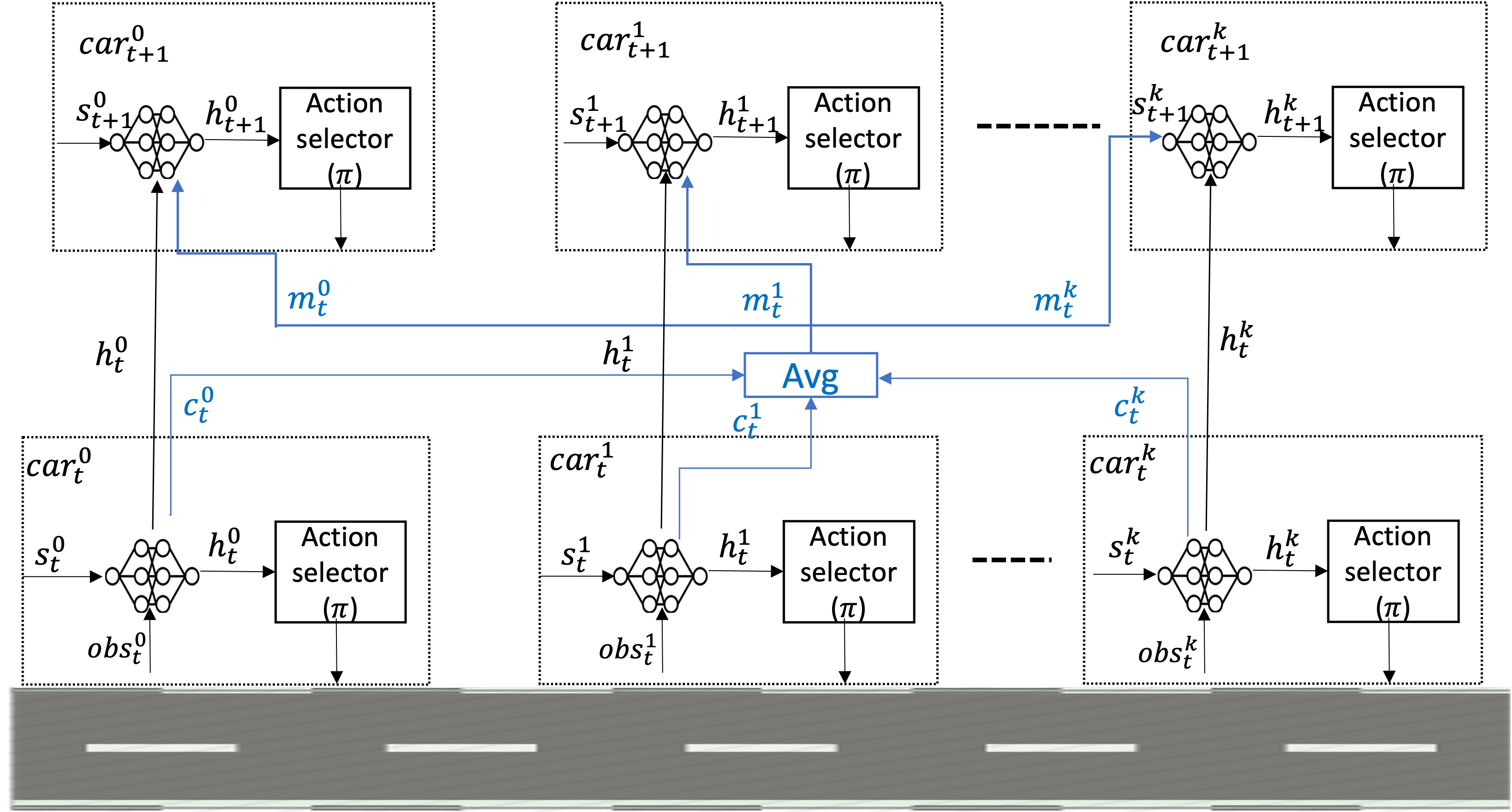
Joe McCalmon, Ashley Peake, Benjamin Raiford, Tongtong Liu , Sarra Alqahtani ICTAI, 2020 [paper] A growing trend in the field of autonomous vehicles is the use of platooning. The design of control algorithms for platoons is challenging considering that coordination among vehicles is obtained through diverse communication channels. In this paper, we propose a multi-agent reinforcement learning approach for autonomous vehicles which communicate in a platoon formation. |
|
Computer and Information Science (UPenn)
Computer Science (Wake Forest)
Mathematics and Statistics (Wake Forest)
|
|
Website source code is adapted from here. |